
[JPA] 페이징 알아가기 1 (MySQL)
들어가며
팀 내에서 JPA를 학습하고 공유하는 스터디를 시작하게 되었어요. 저는 페이징과 관련된 주제를 선택했는데요. 선택한 이유는 다음과 같습니다.
- 현재 모든 조회는
전체 조회를 사용한다. - 사용자가 늘어날 수록 쿠폰 생성률도 증가하게 된다. n * m 으로 쿠폰, 예약, 만남에 관한 데이터가 증가
- 페이징 처리는 필요하게 될 것이고 미리 공부하기 위해 주제를 선택
페이징은?

구글 같은 경우 간단한 검색만 해도 100만개가 넘는 데이터가 조회되는데요. 정말 찾기 힘든 자료가 아닌이상 10페이지를 넘어가는 일이 매우 드뭅니다. 그렇기에 100만개를 사용자에게 보내지 않고 한 페이지에 필요한 개수만큼 데이터를 조회해서 보내준다면 훨씬 적은 리소스를 사용하게 되겠죠?
→ 실제 구글은 1000개 이상의 검색 결과를 제공하지 않는다고 합니다.
MySQL의 페이징 처리
1. OFFSET 을 사용한 페이징 쿼리
MySQL의 페이징 처리는 생각보다 간단합니다. LIMIT과 OFFSET의 개념을 알고 있어야 하는데요.
LIMIT: 얼마나 가져올 것인지
OFFSET: 어디서부터 가져올 것인지
예를 들어 100개의 게시물에서 11번 게시물부터 5개의 게시물을 가져오고 싶다면 LIMIT은 5, OFFSET은 10이 됩니다.
땡쿠팀에서 사용되는 예약 엔티티를 조회해보겠습니다.
Query nativeQuery = entityManager.createNativeQuery(
"SELECT * FROM reservation limit 5 offset 10",
Reservation.class);
List<Reservation> reservations = nativeQuery.getResultList();
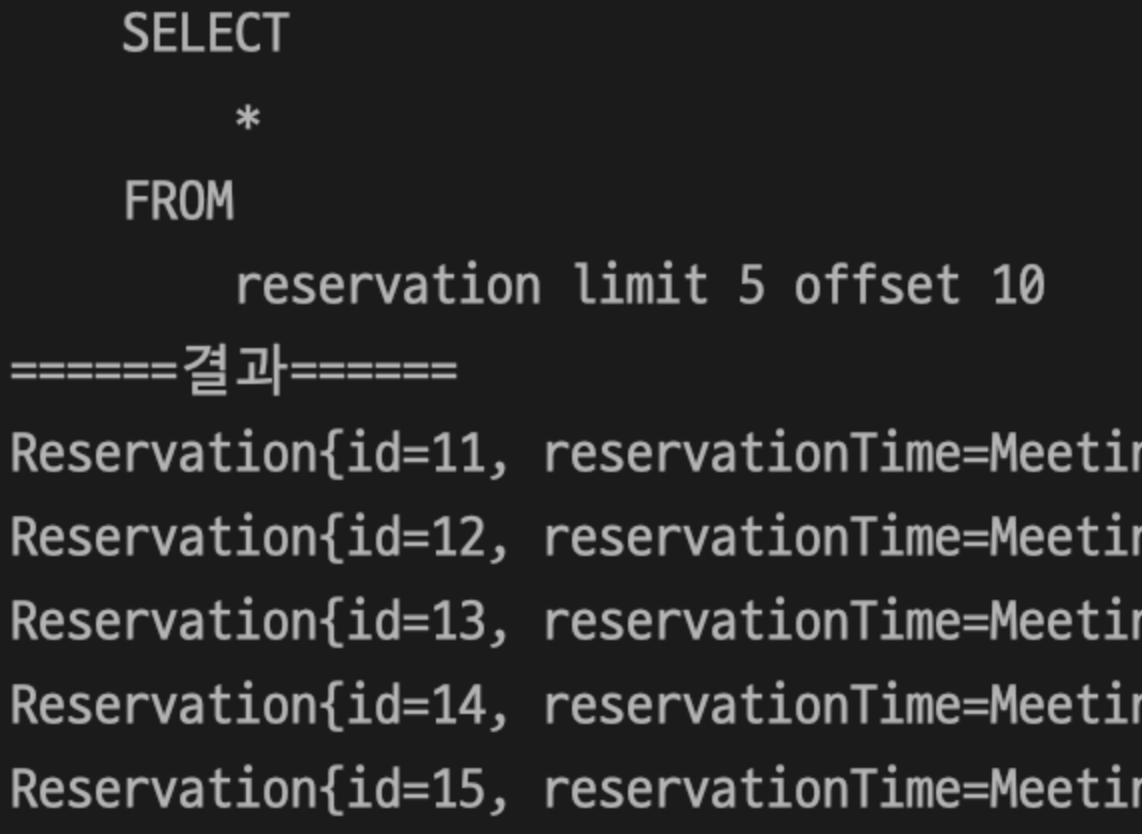
원하는 결과가 출력되었습니다.
🚨 OFFSET 방식의 문제점
offset으로 데이터를 조회하는 방식은 조회하려는 데이터가 많을 수록 느려질 수 밖에 없습니다. 10,000번째부터의 데이터를 가져오기 위해 10,000까지 행을 읽어야하기 때문입니다.
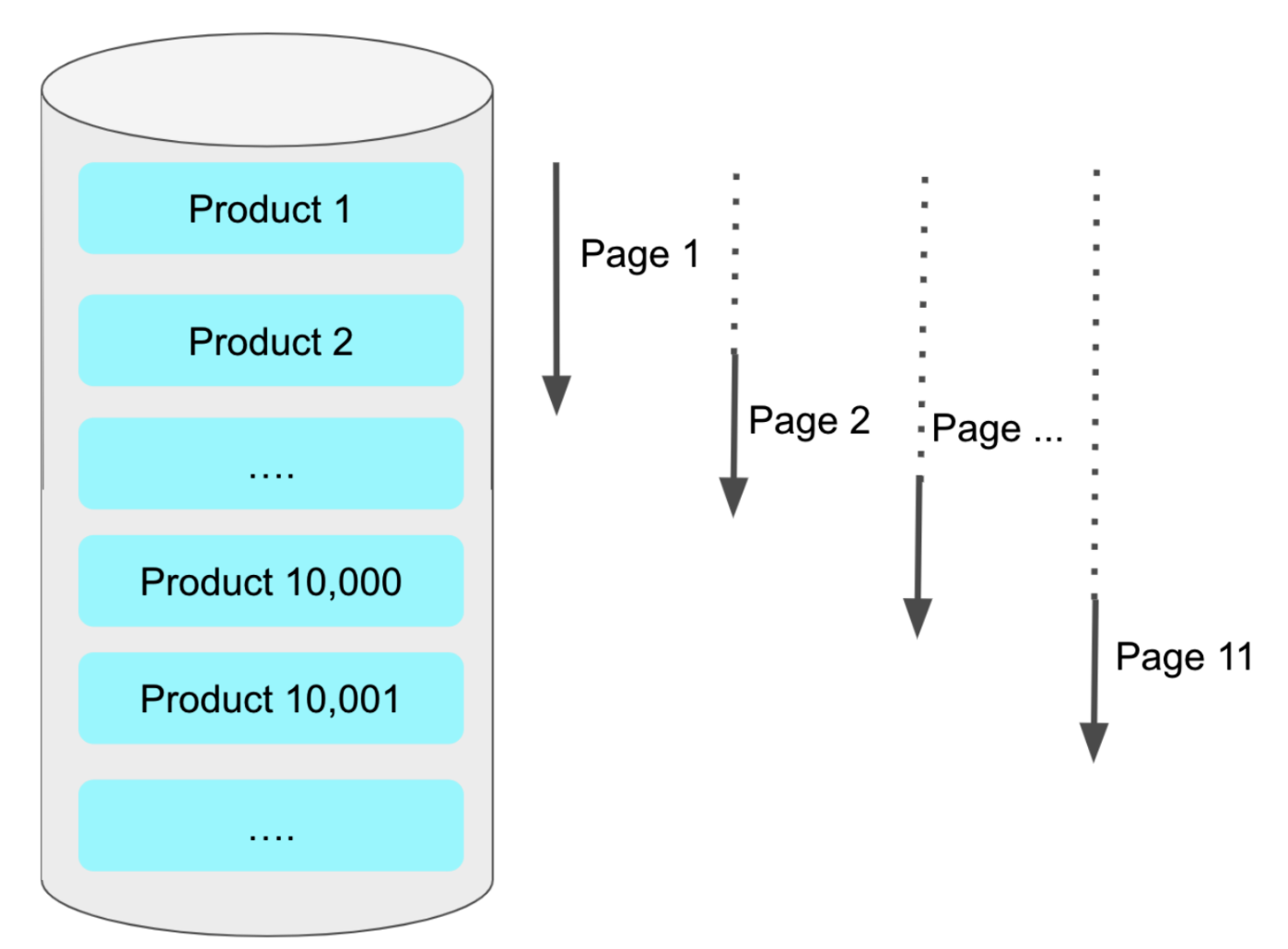
이미지 출처 : https://jojoldu.tistory.com/528
비교해보기
쿠폰과 예약 컬럼을 15만개를 추가하였고 페이징 쿼리를 실행해보았습니다. 테이블 구조는 다음과 같습니다.
mysql> desc coupon;
+-------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+---------+----------------+
| id | bigint | NO | PRI | NULL | auto_increment |
| coupon_type | varchar(20) | NO | | NULL | |
| message | varchar(255) | NO | | NULL | |
+-------------+--------------+------+-----+---------+----------------+
mysql> desc reservation;
+--------------+--------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------+------+-----+---------+----------------+
| id | bigint | NO | PRI | NULL | auto_increment |
| meeting_date | date | NO | | NULL | |
| coupon_id | bigint | NO | MUL | NULL | |
+--------------+--------+------+-----+---------+----------------+
1,001번 부터 10,000개의 데이터 조회 속도 측정
SELECT *
FROM reservation AS r
JOIN coupon AS c
ON r.id = c.id
LIMIT 10000 OFFSET 1000;

14,001번 부터 10,000개의 데이터 조회 속도 측정
SELECT *
FROM reservation AS r
JOIN coupon AS c
ON r.id = c.id
LIMIT 10000
OFFSET 140000;

+----+-------------+-------+------------+--------+---------------+---------+---------+--------------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+---------+---------+--------------+--------+----------+-------+
| 1 | SIMPLE | c | NULL | ALL | PRIMARY | NULL | NULL | NULL | 149810 | 100.00 | NULL |
| 1 | SIMPLE | r | NULL | eq_ref | PRIMARY | PRIMARY | 8 | thankoo.c.id | 1 | 100.00 | NULL |
+----+-------------+-------+------------+--------+---------------+---------+---------+--------------+--------+----------+-------+
현재는 단순한 데이터, 복잡하지 않은 연관관계, 15만개의 데이터를 가지고 측정한 결과이고 더 복잡하고 많은 데이터일수록 그 차이는 더 커지게 됩니다.
2. Late row lookup 을 활용한 페이징
SELECT * FROM reservation as r
JOIN (
SELECT id
FROM reservation
LIMIT 10000
OFFSET 140000
) AS lr
ON r.id = lr.id
JOIN coupon as c
ON r.id = c.id
ORDER BY r.id;

+----+-------------+-------------+------------+--------+---------------+-----------+---------+-------+--------+----------+---------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+--------+---------------+-----------+---------+-------+--------+----------+---------------------------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 149994 | 100.00 | Using temporary; Using filesort |
| 1 | PRIMARY | c | NULL | eq_ref | PRIMARY | PRIMARY | 8 | lr.id | 1 | 100.00 | NULL |
| 1 | PRIMARY | r | NULL | eq_ref | PRIMARY | PRIMARY | 8 | lr.id | 1 | 100.00 | NULL |
| 2 | DERIVED | reservation | NULL | index | NULL | coupon_id | 8 | NULL | 149994 | 100.00 | Using index |
+----+-------------+-------------+------------+--------+---------------+-----------+---------+-------+--------+----------+---------------------------------+
Row lookup와 Late row lookup
Row lookup이란 Index record와 Table record 사이에서 발생하는 Fetching을 의미합니다.
쉽게 설명하면 색인에서 연결된 테이블 레코드로 관계형 자료들의 값을 가져오는 행위입니다. 즉, 이를 위해서 테이블 레코드로 접근하여 해당 자료를 읽는 시간이 필요합니다. 이런 소요시간을 최소화/지연시키는 방법을 Late row lookup입니다.
결국 색인을 적극적으로 활용하여 late row lookup을 최대화하는 것이 SELECT 성능을 큰 향상을 줍니다.
출처 : https://blog.lulab.net/database/optimize-pagination-sql-by-join-instead-of-limit/
→ 아직 위 내용이 이해가 되진 않지만 서브 쿼리를 사용해서 id가 인덱싱이 되어 성능이 더 향상된 것을 알 수 있습니다.
3. Cursor 기반 페이징
Cursor 기반 페이징 방식은 조회 시작 부분을 인덱스로 빠르게 찾아 매번 첫 페이지만 읽도록 하는 방식입니다.
아무리 페이지가 뒤로 가더라도 처음 페이지를 읽은 것과 동일한 성능을 가지게 되므로, Offset 방식보다 훨씬 성능이 개선됩니다.
이 방식은 페이지 번호로 이동되는 서비스에서는 사용할 수 없습니다.. 땡쿠 같은 경우에는 무한 스크롤 같은 방식이 더 좋은 환경이기 때문에 적용할 수 있어 보이네요.
SELECT *
FROM reservation as r
JOIN coupon AS c
ON c.id = r.id
WHERE r.id > 140000
 Late row lookup 방식보다 훨씬 높은 성능을 보여준다.
Late row lookup 방식보다 훨씬 높은 성능을 보여준다.
+----+-------------+-------+------------+-------+---------------+---------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | r | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 19852 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+-------+----------+-------------+
참고 : https://velog.io/@now_iz/페이지네이션-최적화하기
❓ 하지만 번호순으로 페이징처리를 해야하는 서비스에서는 어떻게 처리해야할까? 고민해보는 것도 좋을 듯 합니다.
- 제한된 데이터를 가지고 그 안에서 페이징을 처리하는가??
- 구글같은 경우에는 한 번 조회시 최대 1000건까지만 조회를 한다.
- 2. 페이징 성능 개선하기 - 커버링 인덱스 사용하기
참고 : 페이징 기능을 성능 최적화하기